 شرکت میلتا Mielta Technologies
شرکت میلتا Mielta Technologies شرکت روسما Rossma
شرکت روسما Rossma شرکت کیوریتور Qrator
شرکت کیوریتور Qrator گواهینامه پایداری سیستم B Corp
گواهینامه پایداری سیستم B Corp
NVIDIA Supercharges Hopper، پیشروترین پلتفرم محاسباتی هوش مصنوعی در جهان
بر اساس معماری NVIDIA Hopper™، NVIDIA HGX H200 دارای پردازنده گرافیکی NVIDIA H200 Tensor Core با حافظه پیشرفته است تا حجم انبوهی از دادهها را برای هوش مصنوعی مولد و بارهای کاری محاسباتی با کارایی بالا مدیریت کند.
قدرتمندترین پردازنده گرافیکی جهان
پردازنده گرافیکی NVIDIA H200 Tensor Core، هوش مصنوعی و محاسبات با کارایی بالا (HPC) را با عملکرد و قابلیتهای حافظه تغییر میدهد. به عنوان اولین GPU با HBM3e، حافظه بزرگتر و سریعتر H200 به شتاب هوش مصنوعی و مدلهای زبان بزرگ (LLM) کمک میکند و در عین حال محاسبات علمی را برای حجم های کاری HPC پیش میبرد.
نکات برجسته
عملکرد سطح بعدی را تجربه کنید
High-Performance Computing
110X Faster
GPT-3 175B Inference
1.6X Faster
Llama2 70B Inference
1.9X Faster
فواید
عملکرد بالاتر و حافظه بزرگتر و سریعتر
بر اساس معماری NVIDIA Hopper، NVIDIA H200 اولین پردازنده گرافیکی است که 141 گیگابایت حافظه HBM3e را با سرعت 4.8 ترابایت بر ثانیه (TB/s) ارائه میکند که تقریباً دو برابر ظرفیت NVIDIA H100 Tensor Core GPU با 1.4X است. پهنای باند حافظه بیشتر حافظه بزرگتر و سریعتر H200، هوش مصنوعی و LLM تولیدی را تسریع میکند، در حالی که محاسبات علمی را برای بارهای کاری HPC با بهرهوری انرژی بهتر و هزینه کل مالکیت پایینتر پیش میبرد.
قفل Insights را با استنتاج LLM با کارایی بالا باز کنید
در چشم انداز همیشه در حال تکامل هوش مصنوعی، کسب و کارها برای پاسخگویی به طیف متنوعی از نیازهای استنتاج به LLM ها متکی هستند. یک شتابدهنده استنتاج هوش مصنوعی باید بالاترین توان عملیاتی را در کمترین TCO ارائه دهد که در مقیاس برای یک پایگاه کاربر عظیم مستقر شود.
H200 سرعت استنتاج را تا 2 برابر در مقایسه با پردازندههای گرافیکی H100 در هنگام کار با LLMهایی مانند Llama2 افزایش میدهد.
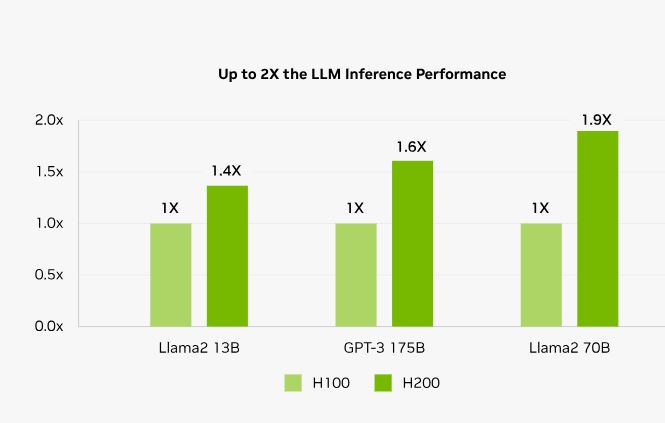
عملکرد اندازه گیری اولیه، در معرض تغییر است.
Llama2 13B: ISL 128، OSL 2K | توان عملیاتی | H100 1x GPU BS 64 | H200 1x GPU BS 128
GPT-3 175B: ISL 80، OSL 200 | پردازنده گرافیکی x8 H100 BS 64 | پردازندههای گرافیکی x8 H200 BS 128
Llama2 70B: ISL 2K، OSL 128 | توان عملیاتی | H100 1x GPU BS 8 | H200 1x GPU BS 32.
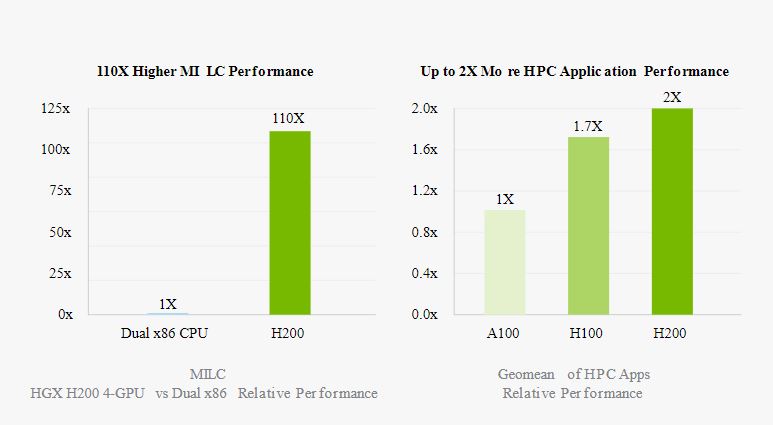
عملکرد پیش بینی شده، ممکن است تغییر کند.
HPC MILC- مجموعه داده NERSC Apex Medium | HGX H200 4-GPU | Sapphire Rapids 8480 دوتایی
HPC Apps- CP2K: مجموعه داده H2O-32-RI-dRPA-96points | GROMACS: مجموعه داده STMV | ICON: مجموعه داده r2b5 | MILC: مجموعه داده NERSC Apex Medium | Chroma: مجموعه داده HMC Medium | اسپرسو کوانتومی: مجموعه داده AUSURF112 | 1x H100 | 1x H200.
محاسبات با کارایی بالا سوپرشارژ
در چشم انداز همیشه در حال تکامل هوش مصنوعی، کسب و کارها برای پاسخگویی به طیف متنوعی از نیازهای استنتاج به LLM ها متکی هستند. یک شتابدهنده استنتاج هوش مصنوعی باید بالاترین توان عملیاتی را در کمترین TCO ارائه دهد که در مقیاس برای یک پایگاه کاربر عظیم مستقر شود.
H200 سرعت استنتاج را تا 2 برابر در مقایسه با پردازندههای گرافیکی H100 در هنگام کار با LLMهایی مانند Llama2 افزایش میدهد.
کاهش انرژی و TCO
با معرفی H200، بهره وری انرژی و TCO به سطوح جدیدی می رسد. این فناوری پیشرفته عملکردی بینظیر را ارائه میکند که همگی در همان مشخصات قدرت H100 هستند. کارخانههای هوش مصنوعی و سیستمهای ابررایانهای که نه تنها سریعتر هستند، بلکه سازگارتر با محیط زیست هستند، یک مزیت اقتصادی ارائه میدهند که هوش مصنوعی و جامعه علمی را به جلو میبرد.
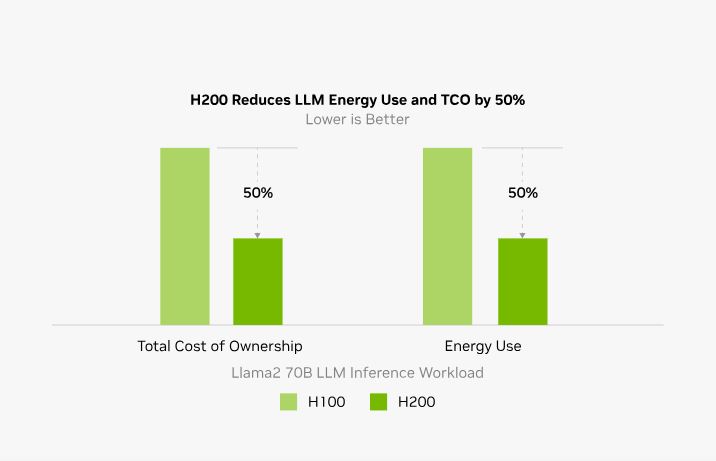
عملکرد اندازه گیری اولیه، در معرض تغییر است.
Llama2 13B: ISL 128، OSL 2K | توان عملیاتی | H100 1x GPU BS 64 | H200 1x GPU BS 128
GPT-3 175B: ISL 80، OSL 200 | پردازنده گرافیکی x8 H100 BS 64 | پردازندههای گرافیکی x8 H200 BS 128
Llama2 70B: ISL 2K، OSL 128 | توان عملیاتی | H100 1x GPU BS 8 | H200 1x GPU BS 32.
کارایی
نوآوری دائمی دستاوردهای عملکرد دائمی را به ارمغان می آورد
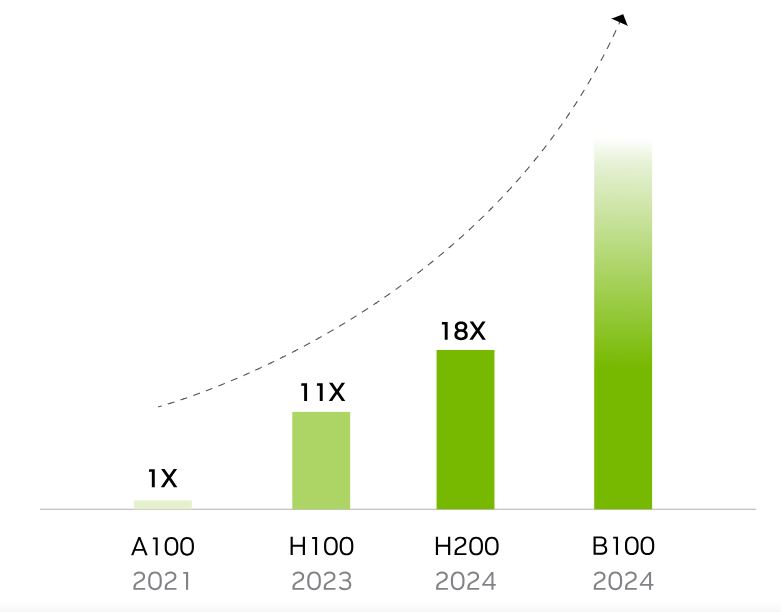
عملکرد اندازه گیری HGX تک گره | A100 آوریل 2021 | H100 TensorRT-LLM اکتبر 2023 | H200 TensorRT-LLM اکتبر 2023
معماری NVIDIA Hopper جهشی عملکردی بیسابقهای را نسبت به مدل قبلی خود ارائه میکند و همچنان از طریق پیشرفتهای نرمافزاری مداوم با H100، از جمله انتشار اخیر کتابخانههای متنباز قدرتمند مانند NVIDIA TensorRT-LLM، به ارتقای سطح خود ادامه میدهد.
معرفی H200 با عملکرد بیشتر به حرکت ادامه می دهد. سرمایه گذاری در آن، رهبری عملکرد را در حال حاضر، و – با بهبود مستمر نرم افزار پشتیبانی شده – در آینده تضمین می کند.
مشخصات فنی
پردازنده گرافیکی NVIDIA H200 Tensor Core
| Form Factor | H200 SXM¹ |
|---|---|
| FP64 | 34 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS |
| FP32 | 67 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS² |
| BFLOAT16 Tensor Core | 1,979 TFLOPS² |
| FP16 Tensor Core | 1,979 TFLOPS² |
| FP8 Tensor Core | 3,958 TFLOPS² |
| INT8 Tensor Core | 3,958 TFLOPS² |
| GPU Memory | 141GB |
| GPU Memory Bandwidth | 4.8TB/s |
| Decoders | 7 NVDEC 7 JPEG |
| Max Thermal Design Power (TDP) | Up to 700W (configurable) |
| Multi-Instance GPUs | Up to 7 MIGs @16.5GB each |
| Form Factor | SXM |
| Interconnect | NVIDIA NVLink®: 900GB/s PCIe Gen5: 128GB/s |
| Server Options | NVIDIA HGX™ H200 partner and NVIDIA-Certified Systems™ with 4 or 8 GPUs |
| NVIDIA AI Enterprise | Add-on |
Nice post! 1754807736